
Introduction
Artificial Intelligence (AI) has become a cornerstone of modern business innovation. Organizations today leverage AI to improve decision-making, streamline operations, reduce costs, and enhance customer experiences. From automating repetitive tasks to predicting market trends, AI is transforming the way businesses operate.
However, the success of an AI project depends heavily on choosing the right AI model. Selecting an inappropriate model can result in inaccurate predictions, wasted resources, and failed initiatives. In this guide, we will explore how to choose the most suitable AI model for different business problems, provide implementation insights, and highlight best practices for achieving success.
Understanding Your Business Problem
Before selecting an AI model, it is essential to understand the problem you are trying to solve. AI is not a magic solution—it must align with business objectives and data.
Key questions to define your business problem:
1. What is the desired outcome?
-
Predictive: Forecast Future Outcomes
-
Predictive AI models are used to analyze historical data and predict future trends or outcomes. Businesses use these models to make smarter decisions based on data rather than guesswork. For example, companies can forecast future sales, estimate product demand, or predict customer behavior. This helps in better planning, reducing risks, and improving business performance. Predictive analytics is widely used in industries like retail, finance, and healthcare to stay ahead of market changes.
-
Classification: Categorize Data into Groups
-
Classification models help businesses organize data into predefined categories or classes. These models are commonly used for tasks like spam detection, fraud detection, and customer segmentation. For example, an email system can classify messages as spam or not spam, while banks can classify transactions as normal or fraudulent. This approach improves decision-making, automation, and accuracy in handling large datasets. Classification is especially useful when businesses need quick and reliable categorization of data.
-
Optimization: Find the Best Possible Solution
- Optimization models focus on finding the most efficient and effective solution under given constraints. These models are used to improve processes such as supply chain management, route planning, and resource allocation. For example, companies can optimize delivery routes to save fuel and time or allocate resources efficiently to reduce costs. This leads to increased efficiency, cost savings, and better utilization of resources. Optimization plays a key role in logistics, manufacturing, and operations management.
2. What type of data is available?
-
Structured Data: Organized Data in Spreadsheets or Databases
-
Structured data refers to well-organized data that is stored in a fixed format, usually in rows and columns like spreadsheets or relational databases. This type of data includes customer records, sales transactions, inventory details, and financial reports. Because it is clean and properly formatted, structured data is easy to search, analyze, and process using AI and machine learning models. Businesses rely heavily on structured data for reporting, analytics, and decision-making. It also ensures faster processing and higher accuracy in predictions.
-
Unstructured Data: Text, Images, Audio, Video
-
Unstructured data is data that does not follow a predefined format or structure, making it more complex to analyze. It includes emails, social media posts, videos, images, audio recordings, and documents. This type of data holds valuable insights about customer preferences, emotions, and behavior. Advanced AI technologies like Natural Language Processing (NLP) and deep learning are used to extract meaningful information from unstructured data. Businesses use it for sentiment analysis, chatbot systems, image recognition, and improving customer experience.
-
Time-Series Data: Sequential Data Such as Stock Prices or Sensor Readings
Time-series data is data collected over time in a sequential order, where each data point is linked to a specific timestamp. Examples include stock market prices, weather data, website traffic, and IoT sensor readings. This type of data helps businesses identify trends, patterns, and seasonal changes. AI models designed for time-series data are widely used for forecasting, demand planning, and real-time monitoring. By analyzing historical trends, businesses can make accurate predictions and proactive decisions to improve performance.
3. What level of accuracy is required?
-
High Accuracy: Critical Tasks Like Fraud Detection and Healthcare Diagnosis
-
High accuracy is essential in situations where even small mistakes can lead to serious consequences. In industries like finance and healthcare, AI models must provide highly precise results to avoid risks such as financial loss or incorrect medical decisions. For example, fraud detection systems must accurately identify suspicious transactions, while healthcare AI must correctly diagnose diseases. These use cases require advanced models, high-quality data, and continuous monitoring to ensure reliability. Businesses must prioritize accuracy over speed in such critical applications.
-
Moderate Accuracy: Tasks Like Product Recommendation or Marketing Analysis
-
Moderate accuracy is acceptable in scenarios where minor errors do not significantly impact business outcomes. For example, recommendation systems suggesting products or marketing analysis predicting customer preferences can tolerate some level of inaccuracy. These systems focus more on improving user experience and engagement rather than perfect precision. Even if the prediction is not 100% correct, it can still provide value by guiding customer choices. This allows businesses to use simpler models and optimize performance without high computational costs.
A clear understanding of the problem ensures that the selected AI model is effective, efficient, and scalable.
Types of AI Models for Business
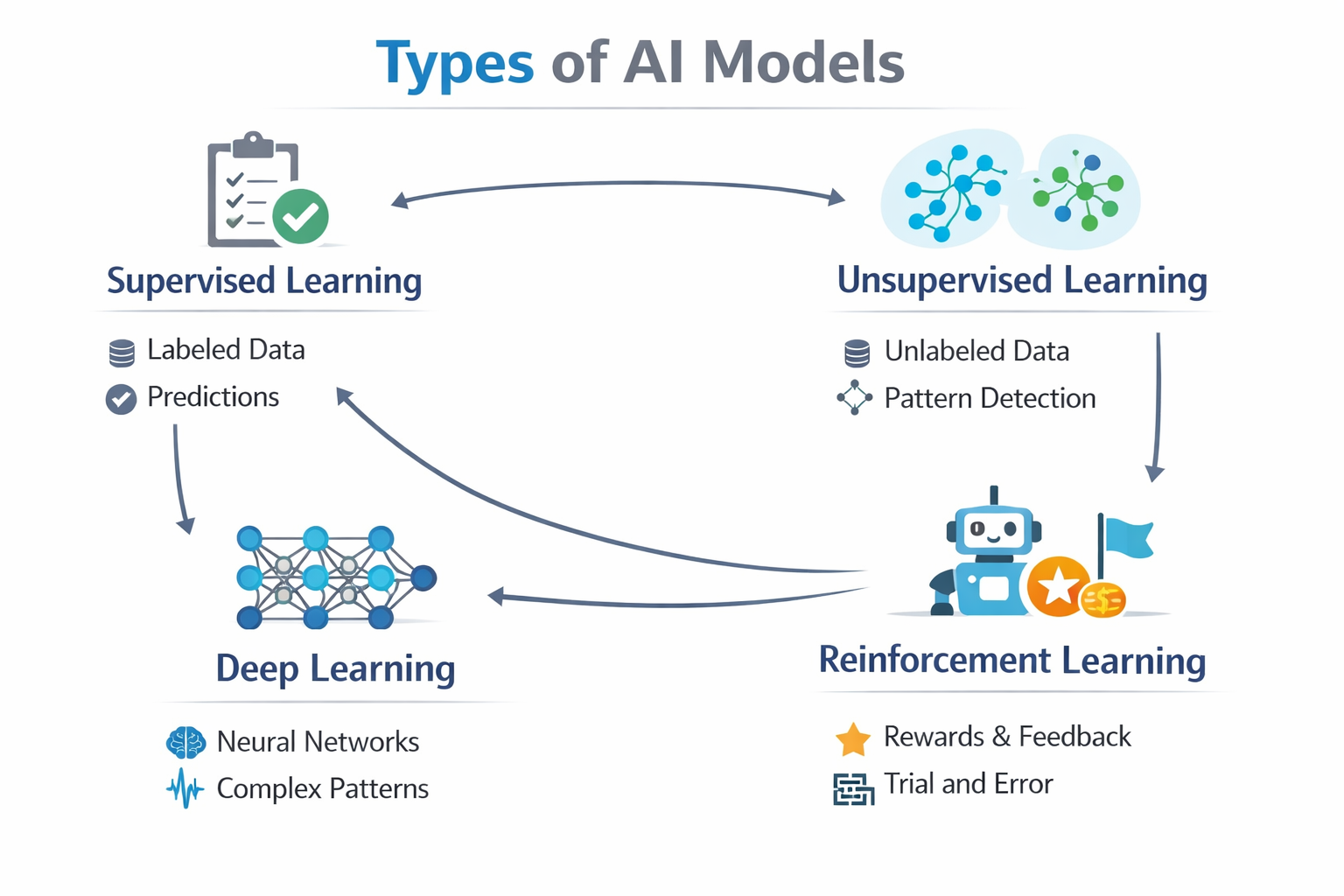
1. Supervised Learning
Supervised learning is one of the most widely used AI approaches in business.
How it Works:
The model is trained using labeled data, meaning each input is associated with a known output. The AI learns patterns in the data to make predictions or classifications.
Business Use Cases:
-
Sales Forecasting: Predict future sales using historical data.
-
Fraud Detection: Identify fraudulent transactions in banking.
-
Customer Churn Prediction: Determine which customers are likely to leave a service.
Implementation Steps:
-
Collect labeled historical data relevant to your problem.
-
Choose a supervised learning algorithm (e.g., linear regression, decision trees, random forests).
-
Split data into training and test sets.
-
Train the model and evaluate accuracy using metrics like RMSE or F1-score.
-
Deploy the model for real-time prediction and monitor performance.
Example:
A telecom company uses supervised learning to predict which customers are likely to switch providers. By analyzing usage patterns, payment history, and service complaints, the company can proactively offer retention plans.
Common Mistakes to Avoid:
-
Using Incomplete or Noisy Data
-
Using incomplete or noisy data can significantly reduce the accuracy of an AI model. Noisy data includes errors, missing values, or irrelevant information that can confuse the model during training. When the data quality is poor, the model may learn incorrect patterns and produce unreliable results. Businesses should focus on data cleaning, preprocessing, and validation before training any AI model. High-quality data ensures better predictions, improved performance, and more trustworthy outcomes.
-
Ignoring Feature Selection
-
Feature selection is the process of choosing the most relevant variables or inputs for an AI model. Ignoring this step can lead to poor model performance and unnecessary complexity. Including too many irrelevant features can confuse the model and reduce accuracy, while selecting the right features helps the model learn faster and perform better. Proper feature selection also improves interpretability and reduces computational cost. Businesses should carefully analyze which features truly impact the outcome before building the model.
-
Overfitting the Model on Historical Data
-
Overfitting occurs when an AI model learns the training data too well, including noise and minor details, instead of general patterns. As a result, the model performs very well on training data but fails on new or unseen data. This leads to poor real-world performance and unreliable predictions. To avoid overfitting, techniques like cross-validation, regularization, and using more diverse data should be applied. A well-balanced model should generalize effectively and provide accurate results across different scenarios.
2. Unsupervised Learning
Unsupervised learning is ideal for discovering hidden patterns in unlabeled data.
How it Works:
The model analyzes data without predefined labels and groups similar data points together or identifies anomalies.
Business Use Cases:
-
Customer Segmentation: Group customers based on behavior for personalized marketing.
-
Market Basket Analysis: Identify products frequently bought together.
-
Anomaly Detection: Detects unusual activity in manufacturing or finance.
Implementation Steps:
-
Gather unlabeled data.
-
Choose an unsupervised learning algorithm (e.g., K-means clustering, hierarchical clustering, PCA).
-
Preprocess and normalize data.
-
Run the algorithm to identify clusters or patterns.
-
Interpret results to inform business decisions.
Example:
An e-commerce company uses unsupervised learning to segment customers into different spending categories. This allows the marketing team to send tailored promotions, increasing conversion rates.
Common Mistakes to Avoid:
-
Using Too Many or Too Few Clusters
-
Choosing the wrong number of clusters is a common mistake in clustering algorithms like K-means. If you use too many clusters, the data becomes over-segmented, making it difficult to identify meaningful patterns. On the other hand, using too few clusters can oversimplify the data and hide important insights. Finding the right balance is important for accurate results. Techniques like the Elbow Method or Silhouette Score can help determine the optimal number of clusters for better decision-making.
-
Ignoring Data Normalization
-
Data normalization is an important preprocessing step that ensures all features are on a similar scale. Ignoring normalization can cause certain variables with larger values to dominate the model, leading to biased or incorrect results. For example, in clustering, distance-based algorithms may give more importance to features with higher numerical ranges. Proper normalization helps improve model accuracy, consistency, and performance. Businesses should always scale their data before applying machine learning algorithms.
-
Misinterpreting Clusters Without Business Context
-
Clusters generated by AI models need to be interpreted carefully with proper business understanding. Without context, clusters may seem meaningful but could lead to incorrect conclusions or decisions. For example, grouping customers based only on purchase frequency may ignore other important factors like demographics or preferences. It is important to combine data insights with domain knowledge to make accurate and useful decisions. Proper interpretation ensures that clustering results provide real business value.
3. Reinforcement Learning
Reinforcement learning (RL) is useful for dynamic decision-making problems.
How it Works:
The AI learns through trial and error, receiving rewards for successful actions and penalties for mistakes. Over time, it optimizes its behavior to maximize rewards.
Business Use Cases:
-
Dynamic Pricing: Adjusting prices based on market demand and competition.
-
Recommendation Systems: Suggesting products or services based on user interactions.
-
Robotics and Automation: Optimizing warehouse operations or autonomous vehicles.
Implementation Steps:
-
Define the environment, actions, and rewards.
-
Select an RL algorithm (e.g., Q-learning, Deep Q Networks).
-
Train the model through simulations or live interactions.
-
Monitor performance and refine the reward strategy.
Example:
A ride-hailing company uses RL to optimize driver allocation during peak hours, improving response time and customer satisfaction.
Common Mistakes to Avoid:
-
Poorly Defined Reward Functions
-
In reinforcement learning, the reward function plays a crucial role in guiding the model’s behavior. If the reward function is poorly defined, the AI system may learn the wrong objectives or optimize for unintended outcomes. For example, a system designed to maximize short-term profit might ignore long-term customer satisfaction if rewards are not balanced properly. A well-designed reward function should align with business goals and desired outcomes. Proper planning ensures the model learns the right strategy and delivers meaningful results.
-
Insufficient Exploration of the Environment
-
Reinforcement learning models need to explore different actions to learn the best possible strategy. If the model does not explore enough, it may get stuck in a suboptimal solution and miss better opportunities. This is known as the exploration vs. exploitation problem. Proper exploration allows the model to discover new patterns and improve performance over time. Businesses should ensure that the model is trained with enough exploration to achieve optimal and reliable decision-making.
-
Ignoring Scalability Constraints
-
Scalability is an important factor when deploying AI models in real-world business environments. Ignoring scalability constraints can lead to performance issues when the system handles large volumes of data or users. For example, a model that works well in testing may fail when deployed at scale due to high computational requirements. Businesses should design AI systems that are efficient, scalable, and capable of handling growth. This ensures long-term sustainability and better return on investment.
4. Deep Learning
Deep learning is a subset of machine learning that excels with complex data such as images, text, and audio.
How it Works:
Uses neural networks with multiple layers to identify intricate patterns and relationships in large datasets.
Business Use Cases:
-
Image Recognition: Detecting defects in manufacturing products.
-
Natural Language Processing (NLP): Analyzing customer reviews or chatbot interactions.
-
Speech Recognition: Converting voice commands to actionable tasks.
-
Healthcare Diagnostics: Detecting diseases from medical images.
Implementation Steps:
-
Collect a large dataset of labeled images, text, or audio.
-
Choose a neural network architecture (e.g., CNN for images, RNN for text).
-
Train the model using GPUs for faster processing.
-
Evaluate using metrics like accuracy, precision, and recall.
-
Deploy and continuously update the model with new data.
Example:
A manufacturing company uses deep learning to inspect products for defects in real-time, reducing quality control costs and improving efficiency.
Common Mistakes to Avoid:
-
Insufficient Data for Training
-
Having insufficient data is one of the most common challenges in building effective AI models. When a model is trained on limited data, it cannot learn meaningful patterns and may produce inaccurate or unreliable predictions. This is especially critical for complex models like deep learning, which require large datasets to perform well. Businesses should focus on collecting, augmenting, and maintaining high-quality data to improve model performance. More data generally leads to better learning and more accurate results.
-
Ignoring Model Interpretability
-
Model interpretability refers to how easily humans can understand and explain the decisions made by an AI system. Ignoring interpretability can be risky, especially in industries like finance, healthcare, and legal sectors where transparency is essential. If stakeholders cannot understand how a model reaches its conclusions, it can reduce trust and make decision-making difficult. Businesses should aim for a balance between accuracy and explainability, ensuring that AI models are both effective and understandable.
-
Overcomplicating Architecture Unnecessarily
-
Using overly complex AI architectures when simpler models can solve the problem is a common mistake. Complex models require more computational power, time, and resources, and they are harder to maintain and interpret. In many cases, simpler models like linear regression or decision trees can perform just as well for certain business problems. Businesses should start with simple models and gradually increase complexity only when needed. This approach saves time, reduces cost, and improves efficiency.
Factors to Consider When Choosing an AI Model
-
Data Quality and Quantity: High-quality, sufficient data is critical for accurate AI predictions.
-
Model Complexity vs Interpretability: Simple models are easier to explain; complex models may achieve higher accuracy.
-
Scalability: Ensure the model can handle growing data volumes and evolving business needs.
-
Cost and Resources: Factor in development costs, computation power, and maintenance requirements.
-
Business Impact: Align the model’s purpose with strategic goals and measurable outcomes.
AI Tools and Platforms for Businesses
Implementing AI is easier with the right tools:
-
Cloud AI Services: AWS SageMaker, Google AI Platform, Azure Machine Learning
-
AutoML Platforms: H2O.ai, DataRobot, Google Cloud AutoML
-
Open-Source Libraries: TensorFlow, PyTorch, scikit-learn, Keras
-
No-Code Platforms: Lobe, Obviously AI, Runway ML
These tools allow businesses of all sizes to implement AI without extensive coding knowledge.
Best Practices for AI Model Selection
-
Define clear business objectives before choosing a model.
-
Conduct thorough data preprocessing and analysis.
-
Test multiple models and compare performance using relevant metrics.
-
Use cross-validation to ensure generalization.
-
Monitor deployed models and continuously retrain for optimal results.
-
Prioritize model interpretability for critical decisions.
FAQs
Q1: Can one AI model solve all business problems?
Ans: No, different problems require different AI models. Predictive models are not suitable for clustering or optimization tasks.
Q2: How much data is needed for AI?
Ans: Depends on the problem and model type. Deep learning needs large datasets; simple models need less.
Q3: How can I evaluate AI model performance?
Ans: Use metrics like accuracy, precision, recall, F1 score, ROC-AUC, or business KPIs.
Q4: Can small businesses afford AI?
Ans: Yes, cloud AI services, pre-trained models, and no-code platforms make AI accessible.
Q5: How do I avoid overfitting?
Ans: Use cross-validation, regularization, and ensure sufficient training data.
Q6: Should I hire AI experts?
Ans: Yes, especially for complex models or critical business applications.
Q7: How long does it take to implement AI?
Ans: Varies by problem complexity and data readiness. Small projects may take weeks; larger systems may take months.
Q8: Can AI replace human decision-making?
Ans: AI complements human decision-making but should not fully replace critical judgment.
Q9: How often should I retrain my AI model?
Ans: Regularly, whenever new data becomes available or performance declines.
Q10: Are AI models industry-specific?
Ans: Some models require customization for specific industries, like healthcare or finance, due to regulatory requirements and domain knowledge.
Conclusion
Selecting the right AI model is a strategic decision that directly influences business success. By understanding your problem, analyzing data, considering model complexity, and leveraging the right tools, businesses can unlock the full potential of AI.
With the right AI model, businesses can:
-
Increase Operational Efficiency: Streamline processes to save time, reduce costs, and improve productivity.
-
Enhance Customer Experiences: Deliver faster, personalized, and seamless experiences that keep customers coming back.
-
Make Data-Driven Decisions: Use insights from your data to make smarter, more accurate business choices.
-
Gain a Competitive Advantage: Stay ahead in your industry by leveraging technology and innovation effectively.
AI is not a one-size-fits-all solution. Careful planning, iterative testing, and continuous improvement are key to achieving meaningful results.






Shreyans Padmani
Shreyans Padmani has 5+ years of experience leading innovative software solutions, specializing in AI, LLMs, RAG, and strategic application development. He transforms emerging technologies into scalable, high-performance systems, combining strong technical expertise with business-focused execution to deliver impactful digital solutions.